Een van de redenen waarom meta-analyse zo nuttig kan zijn, is dat het ons in staat stelt om verschillende onnauwkeurige bevindingen te combineren tot een nauwkeuriger resultaat. In de meeste gevallen leveren meta-analyses schattingen op met kleinere betrouwbaarheidsintervallen dan die van de geïncludeerde onderzoeken. Dit is vooral nuttig als het werkelijke effect klein is. Terwijl primaire onderzoeken misschien niet in staat zijn om de significantie van een klein effect vast te stellen, kunnen meta-analytische schattingen vaak de statistische kracht leveren die nodig is om na te gaan of zo’n klein effect bestaat.
Gebrek aan statistisch vermogen kan echter nog steeds een belangrijke rol spelen, zelfs bij meta-analyses. Het aantal geïncludeerde onderzoeken in veel meta-analyses is klein, vaak minder dan \(K= 10\). Het mediane aantal onderzoeken in Cochrane systematische reviews is bijvoorbeeld zes. Dit alles wordt nog problematischer als we rekening houden met het feit dat meta-analyses vaak subgroepanalyses en meta-regressie omvatten, waarvoor nog meer power nodig is. Bovendien vertonen veel meta-analyses een hoge heterogeniteit tussen studies. Dit vermindert ook de algehele precisie en dus de statistische power.
Het idee achter statistisch vermogen is afgeleid van klassieke hypothesetests. Het houdt rechtstreeks verband met de twee soorten fouten die in een hypothesetest kunnen optreden. De eerste fout is het accepteren van de alternatieve hypothese (bijvoorbeeld \(\mu1 \neq \mu2\)) terwijl de nulhypothese (\(\mu1= \mu2\)) waar is. Dit leidt tot vals positief, ook wel een Type I of \(\alpha\) fout genoemd. Omgekeerd is het ook mogelijk dat we de nulhypothese aannemen, terwijl de alternatieve hypothese waar is. Dit leidt tot vals-negatief, ook wel een Type II- of \(\beta\)-fout genoemd.
Het is gebruikelijk om aan te nemen dat een type I-fout ernstiger is dan een type II-fout. Daarom wordt het \(\alpha\)-niveau gewoonlijk vastgesteld op \(0,05\) en het \(\beta\)-niveau op \(0,2\). Dit leidt tot een drempel van \(1-\beta = 1 - 0,2 = 80%\). Dit leidt tot een drempel van \(1-\beta = 1 - 0,2 = 80%\), die gewoonlijk wordt gebruikt om te bepalen of de statistische power van een test voldoende is of niet.
14.2 Fixed-Effect Model
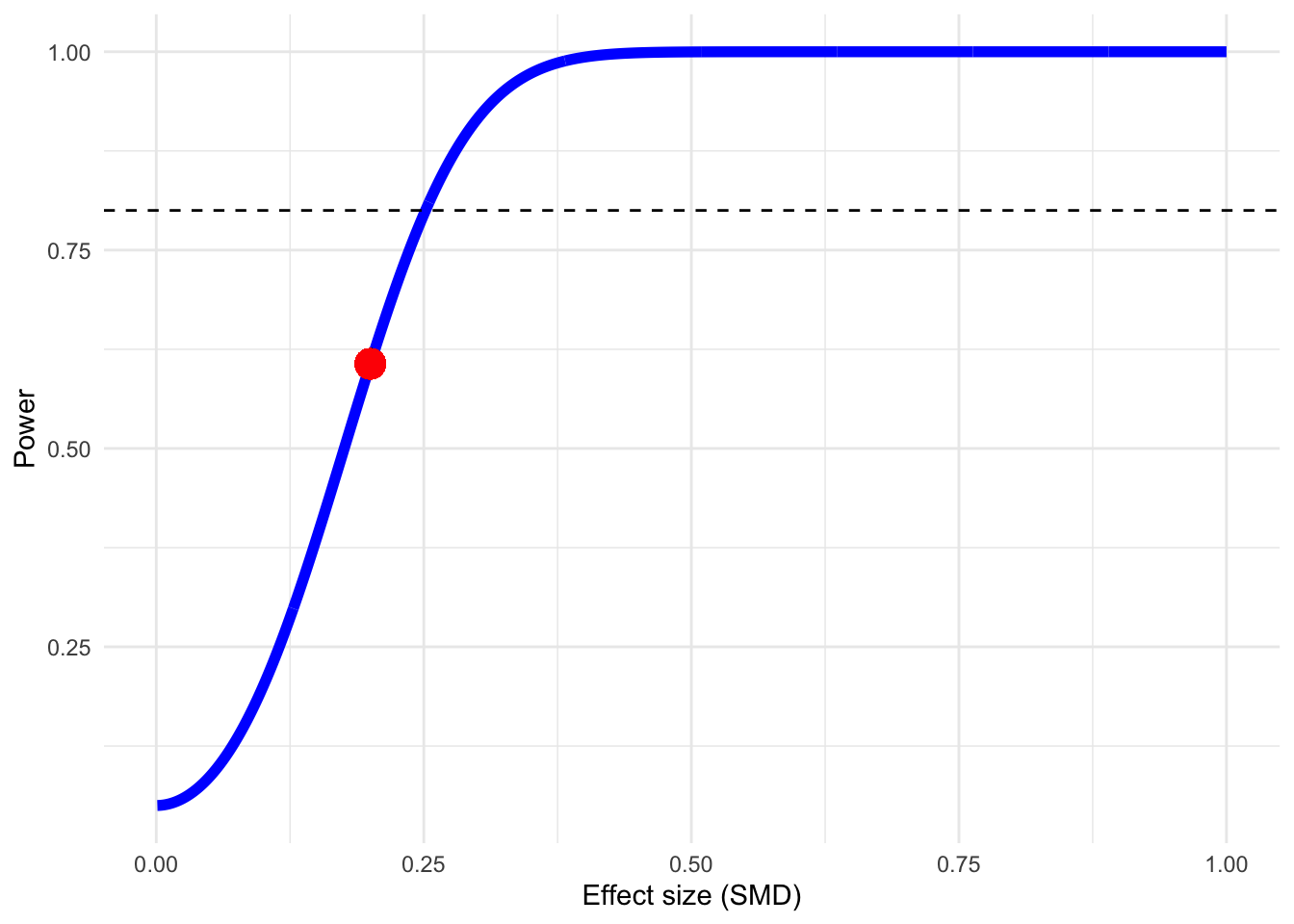
Met R kun je goed de power van de meta-analyse berekenen, bv. die van een fixed-effect model. Stel dat we \(K= 10\) onderzoeken verwachten, elk met ongeveer 25 deelnemers in beide groepen. We willen een effect van \(SMD = 0,2\) kunnen detecteren. Welke power heeft zo’n meta-analyse?
We zien dat een dergelijke meta-analyse met 60,6% te weinig power heeft, ook al zijn er 10 studies geïncludeerd. Een handigere manier om de power van een (fixed-effect) meta-analyse te berekenen is door de functie power.analysis te gebruiken, met verschillende argumenten zoals d, OR, k, n1en n2, p en heterogenity.
library(dmetar)
Extensive documentation for the dmetar package can be found at:
www.bookdown.org/MathiasHarrer/Doing_Meta_Analysis_in_R/
power.analysis(d =0.2, k =10, n1 =25, n2 =25, p =0.05)
Fixed-effect model used.
Warning in geom_point(aes(x = es, y = power), color = "red", size = 5): All aesthetics have length 1, but the data has 1000 rows.
ℹ Did you mean to use `annotate()`?
Power: 60.66%
14.3 Random-Effects Model
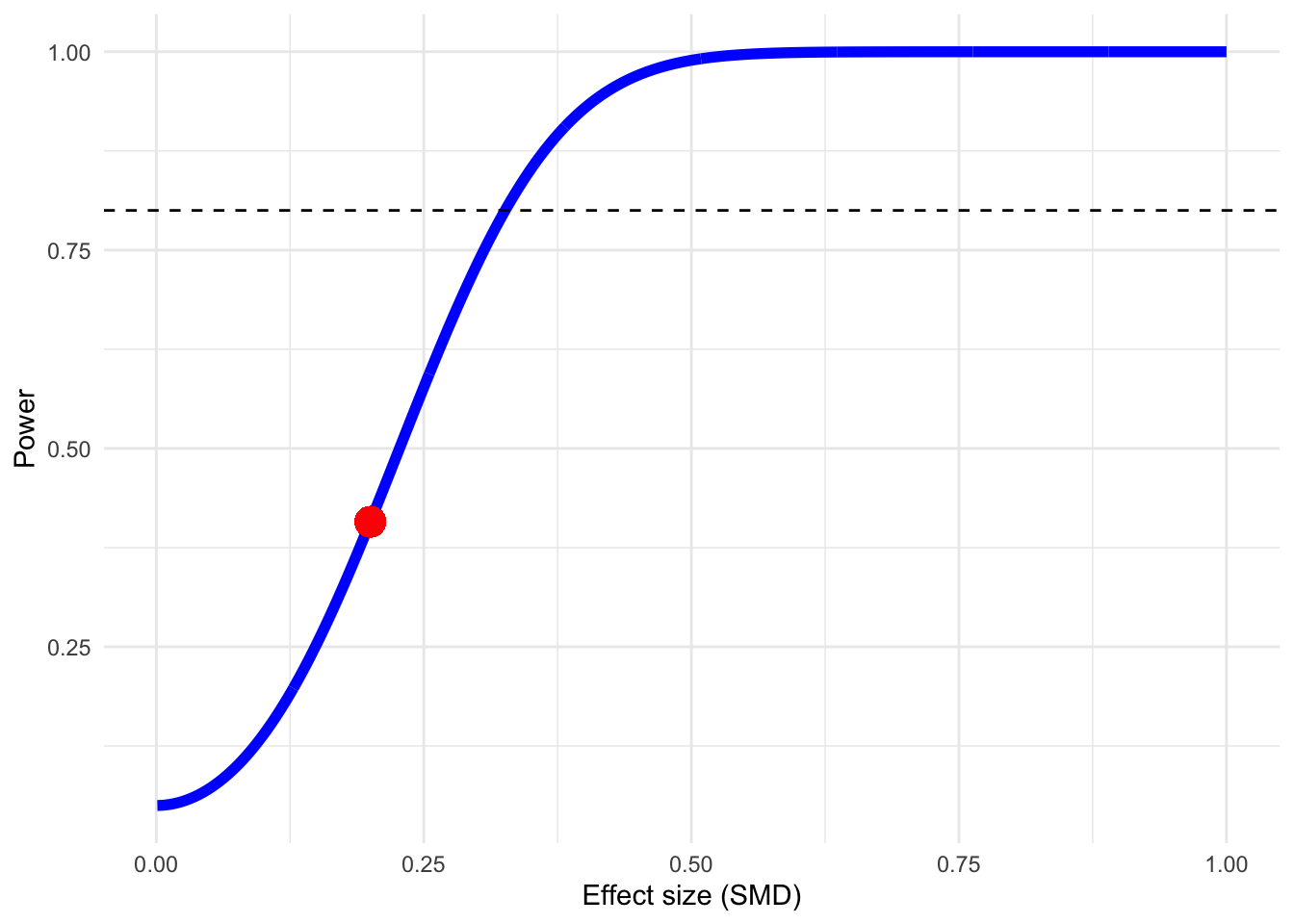
De power.analysis-functie kan ook worden gebruikt voor random-effects meta-analyses. De hoeveelheid aangenomen heterogeniteit tussen studies kan worden geregeld met het argument heterogeniteit. Mogelijke waarden zijn “laag”, “matig” en “hoog”. Laten we nu, met dezelfde waarden als in het vorige voorbeeld, de verwachte power berekenen als de heterogeniteit tussen studies matig is.
power.analysis(d =0.2, k =10, n1 =25, n2 =25, p =0.05,heterogeneity ="moderate")
Random-effects model used (moderate heterogeneity assumed).
Warning in geom_point(aes(x = es, y = power), color = "red", size = 5): All aesthetics have length 1, but the data has 1000 rows.
ℹ Did you mean to use `annotate()`?
Power: 40.76%
14.4 Subgroep analyse
Bij het plannen van subgroepanalyses kan het relevant zijn om te weten hoe groot het verschil tussen twee groepen moet zijn zodat we het kunnen detecteren, gegeven het aantal studies dat we tot onze beschikking hebben. Dit is waar een poweranalyse voor subgroepverschillen kan worden toegepast. Een poweranalyse voor subgroepen kan worden uitgevoerd in R met de functie power.analysis.subgroup.
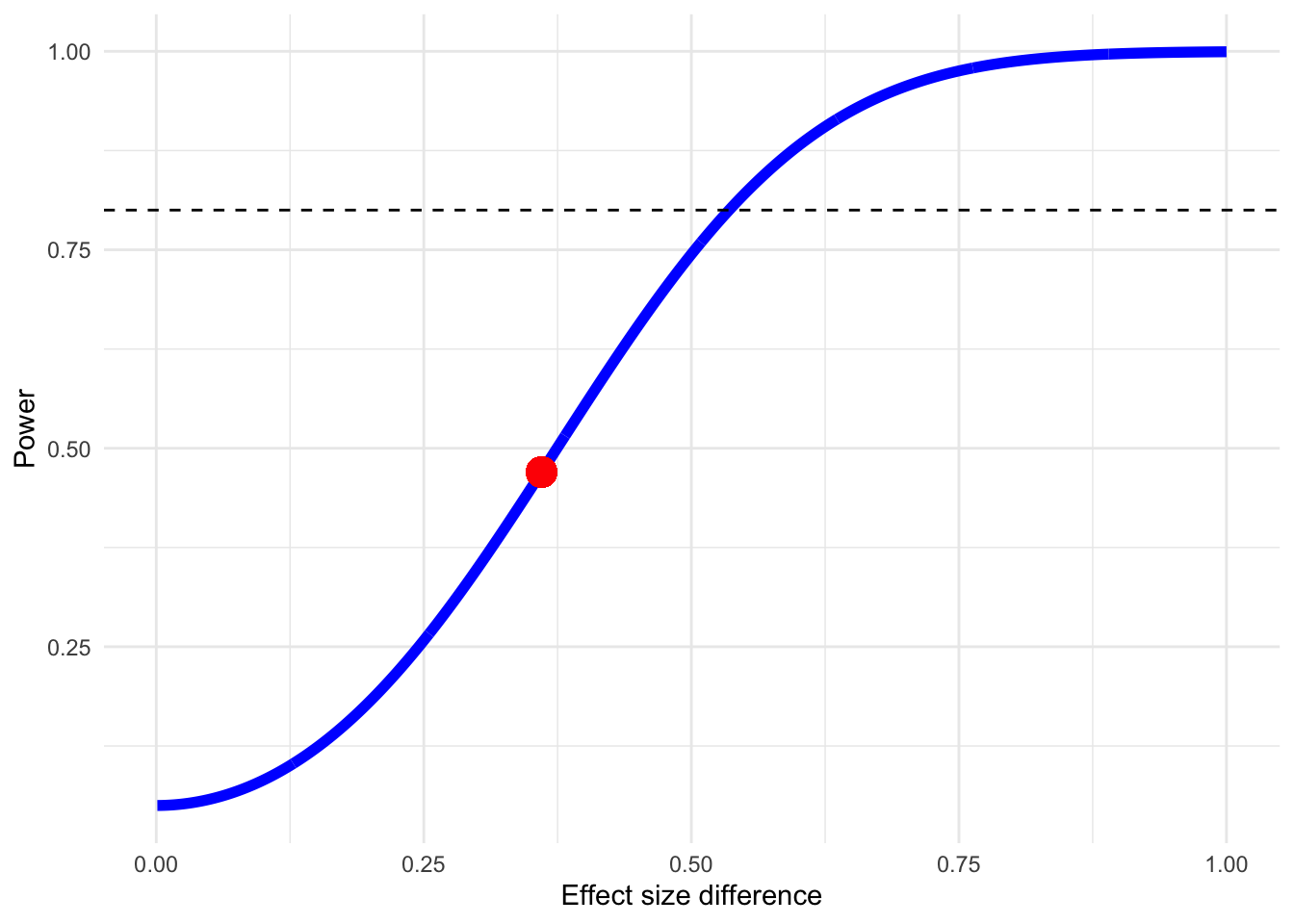
Laten we aannemen dat we verwachten dat de eerste groep een effect heeft van \(SMD = 0,3\) met een standaardfout van 0,13, terwijl de tweede groep een effect heeft van \(SMD = 0,66\) en een standaardfout van 0,14. We kunnen deze aannames gebruiken als invoer voor onze aanroep van de functie:
Minimum effect size difference needed for sufficient power: 0.536 (input: 0.36)
Power for subgroup difference test (two-tailed): 46.99%
Warning in geom_point(aes(x = gamma, y = twotail), color = "red", size = 5): All aesthetics have length 1, but the data has 1000 rows.
ℹ Did you mean to use `annotate()`?
In de uitvoer kunnen we zien dat de power van onze denkbeeldige subgroeptoets (47%) niet voldoende zou zijn. De uitvoer vertelt ons ook dat, ceteris paribus, het verschil in effectgrootte ten minste 0,54 moet zijn om voldoende power te bereiken.