Publicatiebias treedt op wanneer sommige studies systematisch ontbreken in de gepubliceerde literatuur, en dus ook in onze meta-analyse. Strikt genomen is er sprake van publicatiebias als de waarschijnlijkheid dat een studie gepubliceerd wordt afhangt van de resultaten. Er is echter ook een reeks andere vertekeningen in de rapportage. Deze vertekeningen beïnvloeden ook hoe waarschijnlijk het is dat een bevinding in onze meta-analyse terechtkomt. Voorbeelden zijn citatiebias, taalbias of uitkomstbias. Het is ook mogelijk dat gepubliceerd bewijs vertekend is, bijvoorbeeld door twijfelachtige onderzoekspraktijken. Twee veelvoorkomende van dat soort praktijken zijn \(p\)-hacking (doorgaan tot de geschikte \(p\)-waarde bereikt is) en HARKing (hypothese opstellen nadat de resultaten bekend zijn). Beide kunnen het risico op overschatting van effecten in een meta-analyse vergroten.
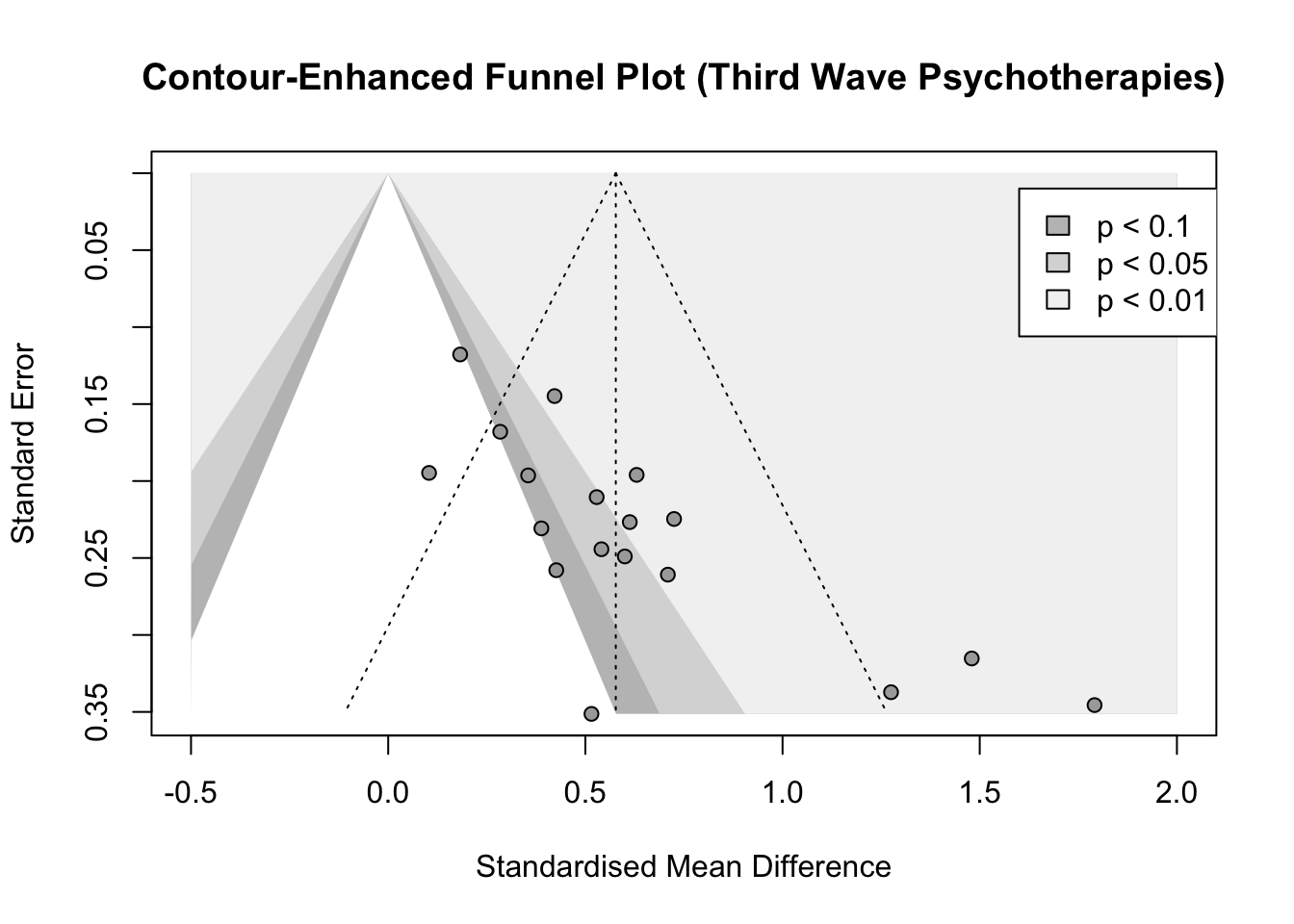
Veel methoden voor publicatiebias zijn gebaseerd op het idee van kleine-studie-effecten. Deze benaderingen gaan ervan uit dat alleen kleine studies met een verrassend hoge effectgrootte significante resultaten behalen en daarom worden geselecteerd voor publicatie. Dit leidt tot een asymmetrische funnel plot, wat een teken kan zijn van publicatiebias. Maar dat hoeft niet zo te zijn. Er zijn ook verschillende “goedaardige” oorzaken van effecten van kleine studies mogelijk.
Een relatief nieuwe methode, p-curve, is gebaseerd op het idee dat we kunnen controleren op bewijskracht door alleen maar te kijken naar het patroon van significante (\(p<0,05\)) effecten in onze gegevens. Deze methode kan worden gebruikt om te testen op zowel de aan- als afwezigheid van een echt effect en kan de grootte ervan schatten.
Er is geen bewijs dat een bepaalde publicatiebias beter veel beter is dan een ander. Maar wat moet je dan kiezen? Om dit probleem aan te pakken, raden we aan om altijd meerdere methoden te gebruiken bij het evalueren van publicatiebias. Hieronder vind je een overzicht van de meest gebruikte methoden met de voor- en nadelen erbij.
library(kableExtra)library(dplyr)library(stringr)dat = readxl::read_excel("data/pubbias_procon.xlsx")dat$Voordelen =str_replace_all(dat$Voordelen, "BREAK", "")dat$Nadelen =str_replace_all(dat$Nadelen, "BREAK", "")colnames(dat)[1] =" "dat[1,1]<-c("Duval & Tweedie Trim-and-Fill")kable(dat %>%mutate_all(linebreak), "html", booktabs = T, escape =FALSE, align ="l", longtable = T, caption ="Methoden om de ware effectgrootte te schatten, gecorrigeerd voor publicatiebias: Overzicht van voor- en nadelen.") %>%kable_styling(latex_options =c("repeat_header"), bootstrap_options =c("condensed", "striped"),font_size =15) %>%row_spec(0, bold=TRUE) %>%column_spec(1, width ="2cm", bold = T) %>%column_spec(2, width ="4cm") %>%column_spec(3, width ="5cm") %>%column_spec(1, italic=FALSE)
Methoden om de ware effectgrootte te schatten, gecorrigeerd voor publicatiebias: Overzicht van voor- en nadelen.
Voordelen
Nadelen
Duval & Tweedie Trim-and-Fill
Zeer veel gebruikt in de praktijk. Kan door veel onderzoekers worden geïnterpreteerd.
Corrigeert de effectgrootte vaak niet voldoende, bijvoorbeeld als het werkelijke effect nul is. Niet robuust als de heterogeniteit erg groot is; presteert vaak beter dan andere methoden.
PET-PEESE
Gebaseerd op een eenvoudig en intuïtief model. Eenvoudig te implementeren en te interpreteren.
Over- of onderschat het effect soms enorm. Zwakke prestaties voor meta-analyses met weinig studies, lage steekproefgroottes en hoge heterogeniteit.
Limit Meta-Analysis
Vergelijkbare benadering als PET-PEESE, maar modelleert expliciet de heterogeniteit tussen studies.
De prestaties zijn minder goed onderzocht dan die van andere methoden. Kan falen als het aantal onderzoeken erg laag is (<10) en de heterogeniteit erg hoog.
P-Curve
Het is aangetoond dat het beter presteert dan andere methoden (met name trim-and-fill) wanneer aan de aannames wordt voldaan.
Werkt onder de aanname van geen heterogeniteit, wat in de praktijk onwaarschijnlijk is. Vereist een minimum aantal significante effectgroottes. Minder gemakkelijk te interpreteren en te communiceren.
Selection Models
Kan potentieel elk soort verondersteld selectieproces modelleren. Het drieparameterselectiemodel heeft goede prestaties laten zien in simulatiestudies.
Alleen geldig als het selectiemodel het proces van publicatiebias adequaat beschrijft. Veronderstellen dat andere effecten van kleine studies niet relevant zijn. Kan moeilijk te interpreteren zijn en vereist achtergrondkennis.
Het is vaak moeilijk, zo niet onmogelijk, om te weten welke aanpak het meest geschikt is voor onze gegevens en of de resultaten betrouwbaar zijn. Zoals we al eerder zeiden, zal de exacte mate waarin selectieve rapportage onze resultaten heeft beïnvloed altijd onbekend zijn. Maar door verschillende publicatiebias technieken toe te passen, kunnen we iets produceren dat lijkt op een reeks geloofwaardige ware effecten.
Selectiemodellen zijn een zeer veelzijdige methode en kunnen worden gebruikt om verschillende publicatiebiasprocessen te modelleren. Ze geven echter alleen geldige resultaten als het veronderstelde model adequaat is en vereisen vaak een zeer groot aantal onderzoeken. Een zeer eenvoudig selectiemodel, het drieparametermodel, kan ook worden gebruikt voor kleinere datasets. Geen enkele publicatiebiasmethode presteert consistent beter dan alle andere. Het is daarom raadzaam om altijd meerdere technieken toe te passen en de gecorrigeerde effectgrootte voorzichtig te interpreteren. Grondig zoeken naar ongepubliceerd bewijs vermindert het risico van publicatiebias veel beter dan de huidige statistische benaderingen.
9.2 Praktijk
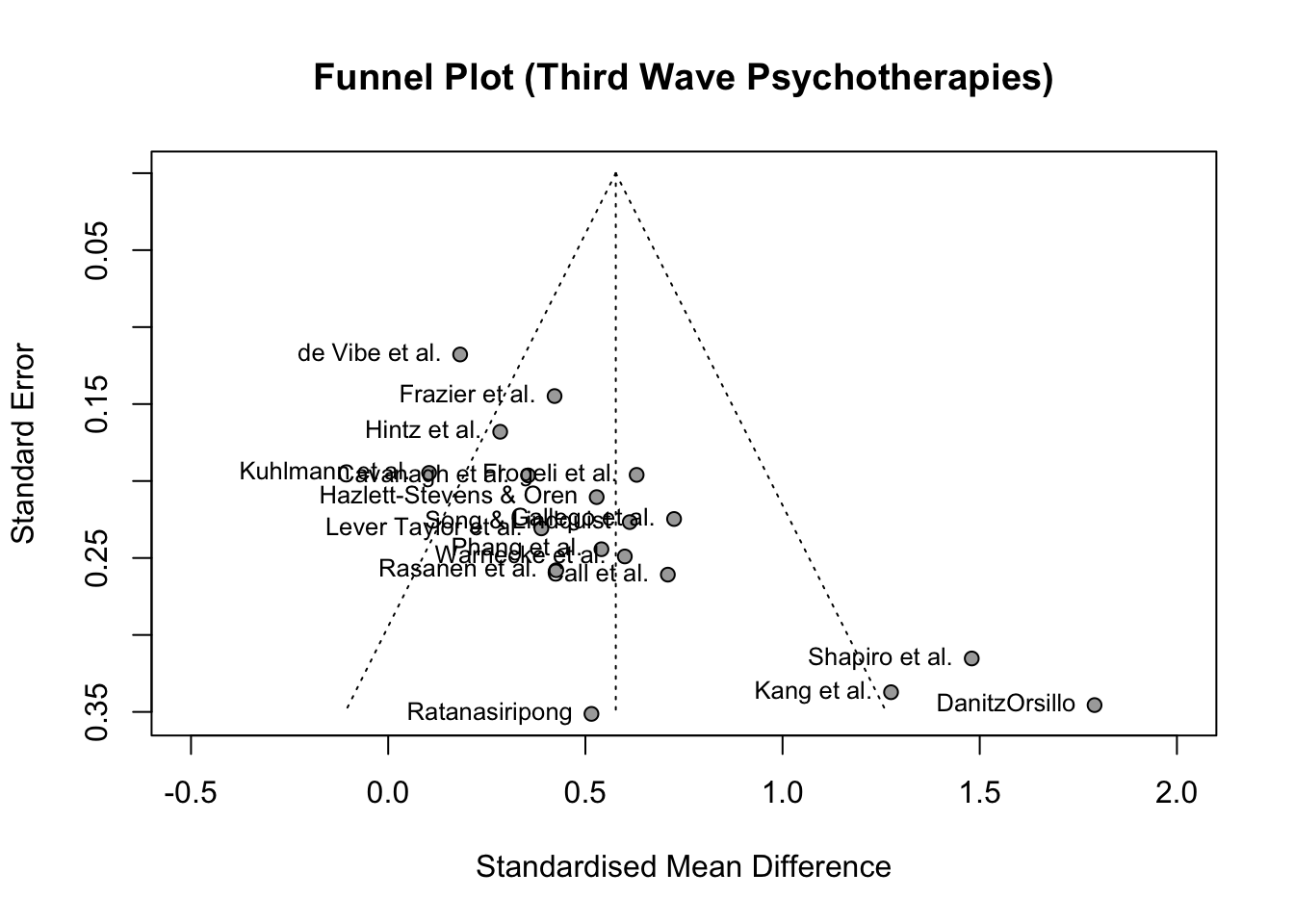
In het praktijkdeel laten we enkel zien hoe je een funnel plot maakt.
library(tidyverse) # voor databewerkinglibrary(dmetar) # voor de datalibrary(meta) # voor de meta-analysedata(ThirdWave)glimpse(ThirdWave)