In meta-regressie passen we conventionele regressietechnieken aan op gegevens op studieniveau. Subgroepanalyses kunnen worden gezien als een speciaal geval van meta-regressie met categorische voorspellers en een gemeenschappelijke schatting van \(\tau^2\). Als mensen over meta-regressie spreken, hebben ze voor een model met een continue variabele als voorspeller in hun hoofd. Dan heb je met een regressie-helling te maken en een bepaalde variabelen wordt vermenigvuldigd met een regressie-gewicht.
Meta-regressiemodellen worden vaak gezien als een uitbreiding van het “normale” random-effectsmodel dat we gebruiken om effectgroottes samen te voegen. Het random-effect model is niets anders dan een meta-regressiemodel zonder hellingterm (slope). Omdat het geen helling bevat, voorspelt het random-effectsmodel simpelweg dezelfde waarde voor elk onderzoek: de schatting van de gepoolde effectgrootte \(\mu\), die gelijk is aan het intercept.
Het doel van een meta-regressiemodel is om (delen van) de ware verschillen in effectgrootte in onze data te verklaren (d.w.z. de heterogeniteitsvariantie tussen studies, \(\tau^2\)). Als een model goed bij de gegevens past, moet de afwijking van de ware effecten van de regressielijn kleiner zijn dan hun oorspronkelijke afwijking van het gepoolde effect. Als dit het geval is, zal de onverklaarde of residuele heterogeniteit klein zijn. Dit wordt weergegeven door de R2∗index, die ons vertelt welk percentage van de heterogeniteitsvariatie door ons model wordt verklaard.
Bij meervoudige meta-regressie (waar in dit notebook verder niet op wordt ingegaan) worden twee of meer voorspellers gebruikt in hetzelfde meta-regressiemodel. Het is ook mogelijk om te testen of de voorspellingen van een variabele veranderen voor verschillende waarden van een andere variabele, door interactietermen te introduceren. Hoewel (meervoudige) meta-regressie erg veelzijdig is, is het niet zonder beperkingen. Meervoudige meta-regressie maakt het erg gemakkelijk om modellen te overfitten, wat betekent dat willekeurige ruis in plaats van echte relaties gemodelleerd worden. Multi-collineariteit van voorspellers kan ook een bedreiging vormen voor de geldigheid van ons model. Er zijn verschillende manieren om ervoor te zorgen dat ons meta-regressiemodel robuust is. We kunnen bijvoorbeeld alleen modellen passen die gebaseerd zijn op een vooraf gedefinieerde theoretische rationale, of permutatietesten gebruiken. Multi-model inferentie kan worden gebruikt als een verkennende aanpak. Deze methode kan ons wijzen op mogelijk belangrijke voorspellers en kan worden gebruikt om hypotheses af te leiden die in toekomstig onderzoek moeten worden getest.
8.2 Praktijk
8.2.1 Meta-regressie in R
In het {meta}-pakket zit de functie metareg waarmee we een meta-regressie kunnen uitvoeren. We gebruiken weer ThirdWave-dataset.
library(tidyverse) # voor databewerkinglibrary(dmetar) # voor de datalibrary(meta) # voor de meta-analysedata(ThirdWave)glimpse(ThirdWave)
We voeren eerst een meta-analyse uit en passen daarna een meta-regressie toe.
m.gen.reg <-metareg(m.gen, ~year)
We bekijken de resultaten.
m.gen.reg
Mixed-Effects Model (k = 18; tau^2 estimator: REML)
tau^2 (estimated amount of residual heterogeneity): 0.0188 (SE = 0.0226)
tau (square root of estimated tau^2 value): 0.1371
I^2 (residual heterogeneity / unaccounted variability): 29.26%
H^2 (unaccounted variability / sampling variability): 1.41
R^2 (amount of heterogeneity accounted for): 77.08%
Test for Residual Heterogeneity:
QE(df = 16) = 27.8273, p-val = 0.0332
Test of Moderators (coefficient 2):
F(df1 = 1, df2 = 16) = 9.3755, p-val = 0.0075
Model Results:
estimate se tval df pval ci.lb ci.ub
intrcpt -36.1546 11.9800 -3.0179 16 0.0082 -61.5510 -10.7582 **
year 0.0183 0.0060 3.0619 16 0.0075 0.0056 0.0310 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
We zien dat de schatting van de residuele heterogeniteitsvariantie, de variantie die niet wordt verklaard door de voorspeller, \(\hat\tau^2_{unexplained}\)=0.019.
De uitvoer geeft ons ook een \(I^2\)-equivalent, dat ons vertelt dat na inclusie van de voorspeller 29,26% van de variabiliteit in onze gegevens kan worden toegeschreven aan de resterende heterogeniteit tussen studies.
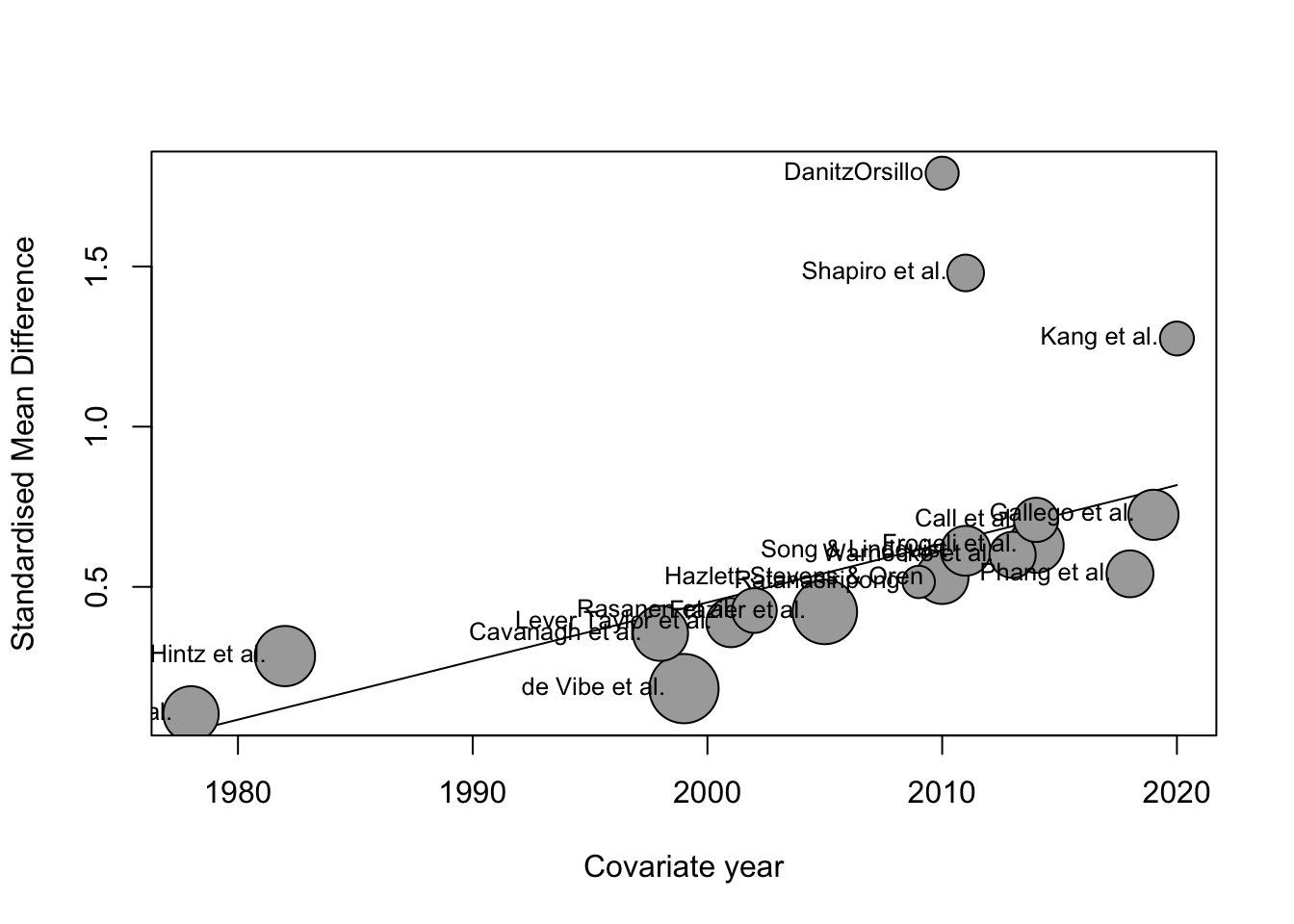
In de laatste regel zien we de waarde van \(R^2_∗\), die in ons voorbeeld 77% is. Dit betekent dat 77% van het verschil in werkelijke effectgrootte kan worden verklaard door het publicatiejaar, een waarde die behoorlijk substantieel is.
Dan zien we Test for Residual Heterogeneity, in wezen de \(Q\)-test. Nu testen we echter of de heterogeniteit die niet wordt verklaard door de voorspeller significant is. We zien dat dit het geval is, met p = 0,03. Er zitten beperkingen aan de Q-toets en moeten daarom niet te veel vertrouwen op dit resultaat.
Het volgende deel toont de Test of Moderators. We zien dat deze test ook significant is (\(p = 0,0075\)). Dit betekent dat onze voorspeller, het publicatiejaar, inderdaad van invloed is op de effectgrootte van de studies.
De laatste paragraaf geeft meer details over de geschatte regressiecoëfficiënten. De eerste regel toont de resultaten voor het intercept (intrcpt). Dit is de verwachte effectgrootte (in ons geval: Hedges’ \(g\)) wanneer onze voorspeller publicatiejaar nul is. In ons voorbeeld vertegenwoordigt dit een scenario dat, aantoonbaar, een beetje gekunsteld is: het toont het voorspelde effect van een onderzoek dat is uitgevoerd in het jaar 0, wat \(\hat{g}= -36,15\) is. Dit herinnert ons er nog maar eens aan dat goede statistische modellen geen perfecte weergave van de werkelijkheid hoeven te zijn; ze moeten gewoon nuttig zijn.
De coëfficiënt waarin we vooral geïnteresseerd zijn, is die in de tweede rij. We zien dat de schatting van het regressiegewicht voor jaar in het model 0,01 is. Dit betekent dat voor elk extra jaar de effectgrootte \(g\) van een onderzoek naar verwachting met 0,01 toeneemt. Daarom kunnen we zeggen dat de effectgroottes van onderzoeken in de loop van de tijd zijn toegenomen. Het 95% betrouwbaarheidsinterval loopt van 0,005 tot 0,3, wat aangeeft dat het effect significant is.
We kunnen met {meta}pakket ook een bubble-plot maken. Dan zie je de regressie-helling van deze meta-regressie.
bubble(m.gen.reg, studlab =TRUE)
We kunnen ook nog eens de subgroep-analyse vanuit meta-regressie raamwerk uitvoeren. We gebruiken de riskbias als categoriale voorspeller. Die variabele zit al ThirdWave-dataset. We kunnen metareg-functie gebruiken en RiskOfBias eraan toevoegen.
In de uitvoer zien we dat de waarde van \(R^2∗\) met 15,66% aanzienlijk kleiner is dan die van het jaar. In overeenstemming met onze eerdere resultaten zien we dat de risk of bias-variabele geen significante effectgrootte voorspeller is (\(p= 0.13\)).
Onder Model Resultats zien we dat metaregRiskOfBias automatisch heeft omgezet in een dummyvariabele. De schatting van het intercept, dat het gepoolde effect van de subgroep “hoog risico” weergeeft, is \(g=0.76\). De schatting van de regressiecoëfficiënt die staat voor studies met een laag biasrisico is -0,29.
Om de effectgrootte voor deze subgroep te krijgen, moeten we het regressiegewicht bij het intercept optellen, wat resulteert in \(g=0.76 - 0.29 \approx 0.47\). Deze resultaten zijn identiek aan die van een subgroepanalyse die uitgaat van een gemeenschappelijke schatting van \(\tau^2\).